此文为宁哥翻译文章,原文章请看这里。
关于DataFrame
上一篇博客我讲到了《基于Python的数据科学技术栈的综述》。这一篇让我们关注一个非常重要的概念:DataFrame。
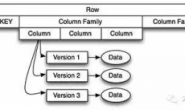
DataFrame非常适合处理结构化数据和半结构化数据,它们基本上是一些行的集合,而每一列都有自己的命名。考虑一下关系型数据库的表,你会发现DataFrame和它非常相似,并支持相似的操作:
对数据切片:在确定的条件下,选择某些行或者列的子集(过滤器)
对某一列或某几列数据进行排序
整合数据,并给出简要性的统计
连接多个DataFrame结构
作为一种漂亮的、类SQL的接口,DataFrame用在一种完全成熟的编程语言中,因此它有比SQL更强大的功能。这就意味着,我们可以在通用编程语言中的任意代码中加入一些解释性的类SQL的操作。
DataFrame在R语言中被普及并被其它语言和框架采用。对于Python来说有Pandas,这是一个非常棒的数据分析型库,而DataFrame也是其中一个非常关键的概念。
Pandas的局限以及Spark下的DataFrame结构
Pandas并不适用于任何场景,它只是一个单机版的工具,因此我们只能在单机上进行操作。此外,Pandas没有内建的并行机制,因此它只能仅仅使用一个CPU内核。
当你处理一个中型数据集(数亿字节)时很可能达到瓶颈,而当你想处理更大的数据集时,Pandas却无能为力。
非常幸运,几个月前Spark社区开源了一种支持DataFrame结构的Spark新版本,与Pandas有相似的接口,但它是重新设计并且支持大数据的。
在Spark DataFrame中有很多非常酷的工程,比如说代码生成、手动内存管理、Catalyst优化器,先抛开这些,关注下它的可用性:
如果你了解Pandas,使用Spark DataFrame的难易程度有多大?
Spark DataFrame有一些怪异模式吗?
有哪些重要的功能性缺失?
我们将举一些例子来对比Pandas和Spark中的DataFrame,然后解决一些我们关注的问题。
让我们开始吧!
对比:Spark相对Pandas的优势
读取数据
Pandas:
>>> data = pd.read_csv("/data/adult-dataset-data.csv")
>>> data.head(1)
Out:
age final_weight workclass education_num
0 39 77516 State-gov 13
Spark:
>>> data = sqlc.load("s3://data/adult-dataset-data.csv", "com.databricks.spark.csv")
>>> data.take(1)
Out:
[Row(age=45.0, final_weight=160962.0, workclass=u' Self-emp-not-inc', education_num=10.0)]
Pandas和Spark中的DataFrame都能很轻易读取多种格式,包括CSV、JSON以及某些二进制格式(其中有的需要依赖额外的库)
注意一点,Spark DataFrame没有index,它不能枚举出列来(对于Pandas来说有列默认的index)。在Pandas中index是特殊的列,如果在Spark DataFrame中我们真需要它,可以选择命名为”index”的列。
切片
Pandas:
>>> sliced = data[data.workclass.isin([' Local-gov', ' State-gov']) \
& (data.education_num > 1)][['age', 'workclass']]
>>> sliced.head(1)
Out:
age workclass
0 39 State-gov
Spark:
>>> slicedSpark = dataSpark[dataSpark.workclass.inSet([' Local-gov', ' State-gov'])
& (dataSpark.education_num > 1)][['age', 'workclass']]
>>> slicedSpark.take(1)
Out:
[Row(age=48.0, workclass=u' State-gov')]
正如你看到的,它们在一个DataFrame结构下的操作非常类似。
还有一个重要的区别。在Pandas中,布尔型切片能得到一个布尔型序列,这就意味着你能利用另外一个长度相同的DataFrame进行过滤。在Spark中你只能在DataFrame的列下进行过滤。
整合
简单的计数:
Pandas:
>>> data.groupby('workclass').workclass.count()
# or shortcut
>>> data.workclass.value_counts()
Out:
workclass
? 1836
Federal-gov 960
...
Spark:
>>> dataSpark.groupBy('workclass').count().collect()
Out:
[Row(workclass=u' Self-emp-not-inc', count=2541),
Row(workclass=u' Federal-gov', count=960),
Row(workclass=u' ?', count=1836),
...]
花式整合:
Pandas:
>>> data.groupby('workclass').agg({'final_weight': 'sum', 'age': 'mean'})
Out:
age final_weight
workclass
? 40.960240 346115997
Federal-gov 42.590625 177812394
Local-gov 41.751075 394822919
...
Spark:
>>> dataSpark.groupBy('workclass').agg({'capital_gain': 'sum', 'education_num': 'mean'}).collect()
Out:
[Row(workclass=u' Self-emp-not-inc', AVG(age)=44.96969696969697, SUM(final_weight)=446221558.0),
Row(workclass=u' Federal-gov', AVG(age)=42.590625, SUM(final_weight)=177812394.0),
...]
语法非常简单,你可以很轻易的进行标准的整合。很遗憾,Spark DataFrame不支持定制化的整合功能,你只能使用内建的一些功能。可以以特定的方式(使用Hive UDAF或者转换成原生RDD)来整合数据,但是这样既不方便又低效。
映射
定义一个函数:
def f(workclass, final_weight):
if "gov" in workclass.lower():
return final_weight * 2.0
else:
return final_weight
Pandas:
>>> pandasF = lambda row: f(row.workclass, row.final_weight)
>>> data.apply(pandasF, axis=1)
Out:
0 155032
1 83311
...
Spark:
>>> sparkF = pyspark.sql.functions.udf(f, pyspark.sql.types.IntegerType())
>>> dataSpark.select(
sparkF(dataSpark.workclass, dataSpark.final_weight).alias('result')
).collect()
Out:
[Row(result=155032.0),
Row(result=83311.0),
...]
正如你看到的,两者都能很容易在某一列或某几列上应用特定的函数,甚至可以重用相同的函数,它们仅仅是在函数封装上有所区别。对于Spark UDFs来说一个小小的不便在于它需要我们指定返回前期类型的函数。
对比:Spark相对Pandas的劣势
以上都是好的方面,Spark和Pandas在使用起来非常相似而且好用。虽然Spark DataFrame比其他大数据工具更易用,但是它毕竟是Spark生态圈中比较年轻的一员,存在一些毛边。让我们看几个例子。
连接
定义两个非常简单的DataFrame用来实现连接的例子:
>>> pandasA = pd.DataFrame([
[1, "te", 1],
[2, "pandas", 4]],
columns=['colX', 'colY', 'colW'])
>>> pandasB = pd.DataFrame([
[3.0, "st", 2],
[4.0, "spark", 3]],
columns=['colY', 'colZ', 'colX'])
>>> sparkA = sqlc.createDataFrame(pandasA)
>>> sparkB = sqlc.createDataFrame(pandasB)
>
Pandas有一个超级简单的语法,就是利用merge方法:
Pandas:
>>> pandasA.merge(pandasB, on='colX', suffixes=('_A', '_B'), how='left')
Out:
colX colY_A colW colY_B colZ
0 1 te 1 NaN NaN
1 2 pandas 4 3 st
Pandas具备一些有用的特征:
指定连接键来替换条件匹配
对于同名的列自动添加后缀
对于连接键仅仅保留一份副本
现在看看Spark中它怎么实现的。
Spark:
>>> joined = sparkA.join(sparkB, sparkA.colX == sparkB.colX, 'left_outer')
>>> joined.toPandas()
Out:
colX colY colW colY colZ colX
0 1 te 1 NaN None NaN
1 2 pandas 4 3 st 2
正如你看到的,Spark DataFrame需要完全的条件匹配,因此它会保留两份副本并且不会添加后缀。这是有问题的,因为我们不能使用df.col来选择列。当你使用collect函数来替代toPandas函数时,结果会令人疑惑,因为它看起来像是第2列覆盖了第1列一样(事实上不是这样的,但是确实令人疑惑)
Spark:
>>> joined.collect()
Out:
[Row(colX=None, colY=None, colW=1, colY=None, colZ=None, colX=None),
Row(colX=2, colY=3.0, colW=4, colY=3.0, colZ=u'st', colX=2)]
为了达到与Pandas同样的效果,我们需要像下面这么做:
Spark:
>>> sparkARenamed = sparkA \
.withColumnRenamed('colY', 'colY_A')
>>> sparkBRenamed = sparkB \
.withColumnRenamed('colX', 'colX_B') \
.withColumnRenamed('colY', 'colY_B')
>>> sparkARenamed.join(sparkBRenamed, sparkARenamed.colX == sparkBRenamed.colX_B, 'left_outer') \
.select('colX', 'colY_A', 'colW', 'colY_B', 'colZ') \
.toPandas()
Out:
colX colY_A colW colY_B colZ
0 1 te 1 NaN None
1 2 pandas 4 3 st
啊,这么差劲!
联合
现在试着联接/联合DataFrame。
Pandas:
>>> pd.concat([pandasA, pandasB])
Out:
colW colX colY colZ
0 1 1 te NaN
1 4 2 pandas NaN
0 NaN 2 3 st
1 NaN 3 4 spark
结果看起来比较合理。Pandas从两个DataFrame中匹配列,并且对于列中缺失数据填充空值(NaNs)
Spark:
>>> sparkA.unionAll(sparkB).collect()
Out:
[Row(colX=1.0, colY=u'te', colW=1),
Row(colX=2.0, colY=u'pandas', colW=4),
Row(colX=3.0, colY=u'st', colW=2),
Row(colX=4.0, colY=u'spark', colW=3)]
很显然这是错误的。Spark的联合功能非常有限,它仅仅在两个DataFrame具有完全相同的模式下才有效(包括列的顺序),但是它不抛出任何错误,所以很容易掉进这个陷阱。
修正Spark的劣势
正如你看到的,Spark有这些劣势,我们能做些什么呢?
看起来像是输入数据的问题,那么我们可以写一个装饰器,来在Spark DataFrame上实现类似Pandas的concat函数。
Spark:
def addEmptyColumns(df, colNames):
exprs = df.columns + ["null as " + colName for colName in colNames]
return df.selectExpr(*exprs)
def concatTwoDfs(left, right):
# append columns from right df to left df
missingColumnsLeft = set(right.columns) - set(left.columns)
left = addEmptyColumns(left, missingColumnsLeft)
# append columns from left df to right df
missingColumnsRight = set(left.columns) - set(right.columns)
right = addEmptyColumns(right, missingColumnsRight)
# let's set the same order of columns
right = right[left.columns]
# finally, union them
return left.unionAll(right)
def concat(dfs):
return reduce(concatTwoDfs, dfs)
现在我们可以以Pandas的风格来连接Spark DataFrame了:
Spark:
>>> concat([sparkA, sparkB]).collect()
Out:
[Row(colX=1, colY=u'te', colW=1, colZ=None),
Row(colX=2, colY=u'pandas', colW=4, colZ=None),
Row(colX=2, colY=u'3.0', colW=None, colZ=u'st'),
Row(colX=3, colY=u'4.0', colW=None, colZ=u'spark')]
作为练习,你可以写一个实现类似Pandas的merge函数。
总结
我仅仅讲了Pandas和Spark下DataFrame性能的一小部分,但是我希望你因此能得到启发。
Spark DataFrame就目前阶段来说是强大的而且易用的,然而却有一些问题,在可用性上仍需要与Pandas缩小差距——在某些方面接口显得太原生并导致非直观的假设,一些重要的如定制化集成的功能模块缺失。欣慰的是,这些都已经在Spark的发展规划内,相信不久的将来这些问题将会被解决。
另一方面,采用定制化的封装能非常方便的扩展基础函数的功能。我们几个月前开始使用Spark并且解决了我们遇到过的几乎所有的问题。
如果你在使用Pandas并且想处理更大规模的数据集,那么使用PySpark和DataFrame吧。
转载请注明:宁哥的小站 » “Pandas”化你的Spark DataFrames