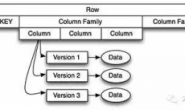
对于计算密集型任务来说,我们可以采用多进程或多线程方式进行操作,也可以采用多台机器进行并行计算,实现效率的大大提升,总得来说,精髓在于对于大数据的“分而治之”。
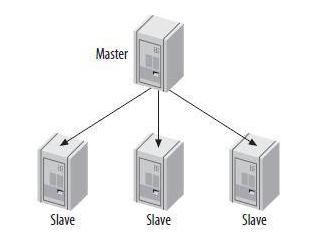
在分布式系统中,一个比较常用的计算结构就是Master/Slave模式。简单来说,Master/Slave与进程与线程的关系类似,在这个结构中,由一台机器作为Master,其他机器作为Slave,因为这些计算单元同时工作,所以也就出现了“集群”的概念。Master作为任务调度者,给多个Slave分配计算任务(Map),最后由Master汇集结果(Reduce),这其实也MapReduce思想所在。
简单实现一下Master和Slave的程序,供大家入门学习:
这里,我们要实现一个Master,用来获取并分配Slave所需要的原始数据,比如说就是一些数字。而对于Slave,通过从Master获取这些数字,并实现打印。
Master.py
rq = RedisQueue('test', host='localhost', port=6379, db=0)
for i in range(30):
rq.put(i)
print rq.qsize()
Slave.py
import time
rq = RedisQueue('test', host='localhost', port=6379, db=0)
while not rq.empty():
print rq.get()
time.sleep(1)
其中, RedisQueue是事先实现好的一个基于Redis的队列,供Master和Slave调用。
这样,我们可以利用同一网段内的多台机器实现并行计算了。首先,在一台作为Master机器上部署Master.py并运行,在内存中挂起数据队列,供剩下的多台作为Slave的机器提取数据。然后分别在每台机器上部署Slave.py并同时运行,可以看到每台机器打印出来的数据是没有重复的,而它们打印出来的所有数据,就是Master机器上挂起的数据。
为了简单展示效果,这里我只采用了2个Slave在Windows系统的笔记本上进行打印。
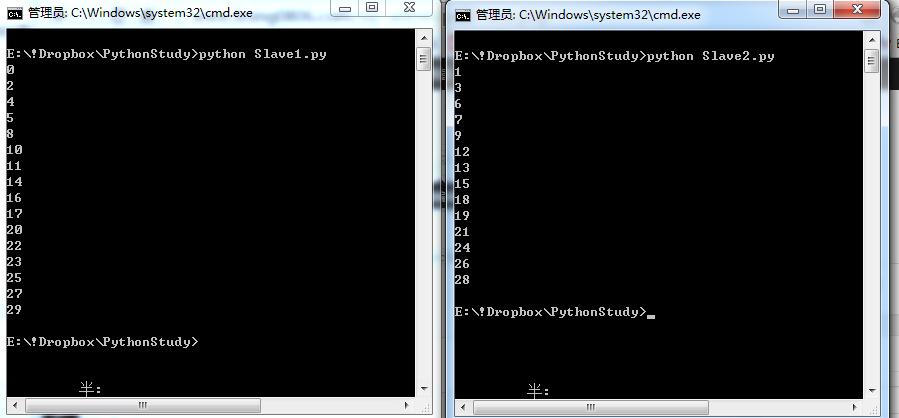
同样道理,当我们采用这种Master/Slave结构实现分布式数据抓取时,可以在一台作为Master的机器上部署所需要的url队列,而剩下的多台作为Slave的机器从这个数据队列中提取url,并对相应网页进行抓取。这样爬虫抓取的效率会大大提升。
转载请注明:宁哥的小站 » Master/Slave分布式计算模式介绍