Pandas
Spark
工作方式
单机single machine tool,没有并行机制parallelism
不支持Hadoop,处理大量数据有瓶颈
分布式并行计算框架,内建并行机制parallelism,所有的数据和操作自动并行分布在各个集群结点上。以处理in...
fireling
9年前 (2016-05-24) 29909℃
99喜欢
此文为宁哥翻译文章,原文章请看这里。
关于DataFrame
上一篇博客我讲到了《基于Python的数据科学技术栈的综述》。这一篇让我们关注一个非常重要的概念:DataFrame。
DataFrame非常适合处理结构化数据和半结构化数据,它们基本上是一些行的集合,而每一列都有自...
fireling
9年前 (2016-05-24) 13376℃
10喜欢
Apache Spark是一种新型的快速通用的集群计算系统,可以和Hadoop交互。
Spark的主要抽象是分布式的条目集合(distributed collection of items),称为RDD(Resilient Distributed Dataset,弹性分布式数据...
fireling
9年前 (2016-05-20) 6635℃
1喜欢
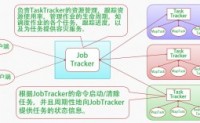
Hadoop采用了MapReduce并行计算框架。MapReduce的实现也采用Master/Slave结构。Master叫做JobTracker,而Slave叫做TaskTracker。用户提交的计算叫做Job,每一个Job会被划分成若干个Tasks。JobTracker负责...
fireling
9年前 (2016-02-04) 10174℃ 0评论
8喜欢
Yarn负责Hadoop的分布式资源调度,它运行于MapReduce之上,提供了高可用性及高扩展性。在部署Hadoop运行环境也可以启动Yarn来进行资源调度。
下面介绍下,在部署Hadoop伪分布式环境基础上,MapReduce任务如何进行Yarn配置。
配置文件修改
...
fireling
9年前 (2016-02-03) 7040℃ 0评论
3喜欢
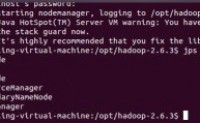
Hadoop是一个开源、高可靠、可扩展的分布式计算框架。它主要包含两个框架:一个是分布式存储框架HDFS,一个分布式计算框架MapReduce,学习Hadoop也主要围绕着这两块问题来。
Hadoop的环境部署,不是太简单。它是基于JVM环境搭建的,如果我们需要多台机器协作,还...
fireling
9年前 (2016-02-02) 7638℃ 0评论
1喜欢