Apache Spark是一种新型的快速通用的集群计算系统,可以和Hadoop交互。
Spark的主要抽象是分布式的条目集合(distributed collection of items),称为RDD(Resilient Distributed Dataset,弹性分布式数据集),它可被分发到集群各个节点上,进行并行操作。RDDs可以通过Hadoop InputFormats创建(如HDFS),或者从其他RDDs转化而来。

安装Scala:
cd /usr/lib
sudo mkdir scala
sudo tar -zxvf ./scala-2.12.0-M3.tgz -C /usr/lib/scala
添加环境变量
vim ~/.bashrc
export SCALA_HOME=/usr/lib/scala/scala-2.12.0-M3
export PATH=${SCALA_HOME}/bin:$PATH
保存退出,输入:source ~/.bashrc
输入scala查看scala版本。
安装Spark:
下载Pre-build with user-provided Hadoop版本也就是“Hadoop free”版本,如spark-1.6.1-bin-without-hadoop.tgz,前提是安装好了Hadoop环境,如/opt/hadoop-2.6.3。
sudo tar -zxvf ./spark-1.6.1-bin-without-hadoop.tgz -C /opt
添加环境变量
vim ~/.bashrc
export SPARK_HOME=/opt/spark-1.6.1-bin-without-hadoop
export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
保存退出,输入:source ~/.bashrc
编辑${SPARK_HOME}/conf/spark-env.sh文件,进入${SPARK_HOME}所在目录:
cp ./conf/spark-defaults.conf.template ./conf/spark-defaults.conf,
cp ./conf/spark-env.sh.template ./conf/spark-env.sh,并修改文件./conf/spark-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_72
export SCALA_HOME=/usr/lib/scala/scala-2.12.0-M3
export HADOOP_HOME=/opt/hadoop-2.6.3
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.6.3/bin/hadoop classpath)
修改文件权限(因为以hadoop用户登录):sudo chown -R hadoop:hadoop /opt/spark-1.6.1-bin-without-hadoop
如果不以hadoop用户登录,直接安装Spark。需要提前在系统中安装好JDK环境,并下载预编译好的版本,如spark-1.6.1-bin-hadoop2.6.tgz,不需要提前安装好Hadoop环境。
交互式Shell:
交互式Shell,目前支持Scala和Python,不支持Java。
对于Scala,可以输入:./bin/spark-shell或者在任何路径直接输入:spark-shell,启动Shell。
对于Python,可以输入:./bin/pyspark或者在任何路径直接输入:pyspark,启动Shell。
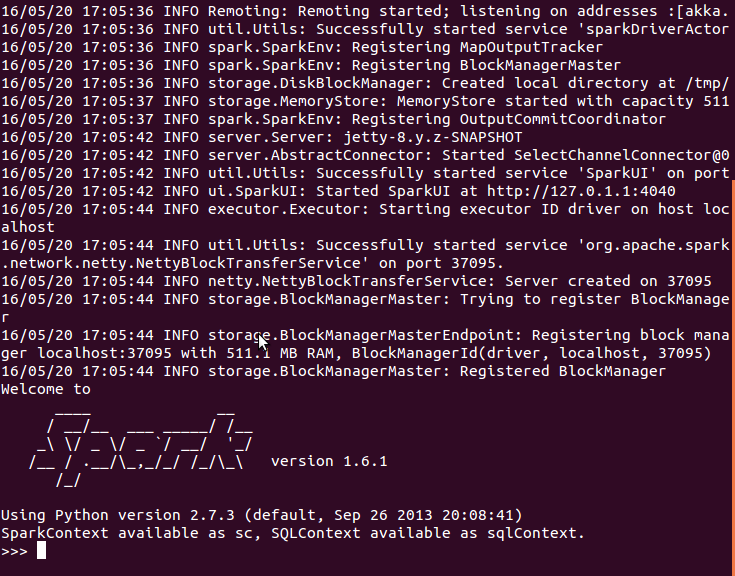
启动成功的界面如下所示,接下来我们可以在命令行中根据需要输入代码了。
转载请注明:宁哥的小站 » Spark环境部署及交互式Shell介绍