网络爬虫是当前互联网比较流行的概念,特别是对于搜索引擎、数据处理等,都需要我们从网上去“取”一些符合要求的数据。总的来说,一般的爬虫分为两个功能模块,也就是取数据和存数据。
取数据是爬虫的关键,特别对于一些具有“防御性”的情况,比如说网站需要登陆的情况,需要挂代理访问的情况,需要限制访问频率的情况,甚至需要输入验证码的情况,都需要在我们设计爬虫方法的时候考虑到。
存数据则是涉及到我们对数据的处理,是保存到数据库中,还是保存到本地文件中,或者临时保存在计算机内存中。
一般所谓的取网页内容,指的是通过程序(某种语言的程序代码,比如Python脚本语言)实现访问某个URL地址,然后获得其所返回的内容(HTML源码,Json格式的字符串等)。然后通过解析规则(比如说正则表达式等),分析出我们需要的数据并取出来。
这里,给大家讲一种最简单的抓取情况,比如说获取一般静态页面的源码(在Chrome浏览器中可以选择右键→查看网页源代码)。如下图,就是网易新闻排行榜页面的源代码,其中这里面有我们想要的数据,比如说一条条的新闻标题和对应的链接。


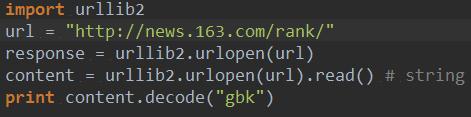
在Python中实现爬虫非常方便,因为Python中有大量的库,有自带的urllib、urllib2,还可以从网上下载requests库。
利用requests库实现爬虫的代码如下:
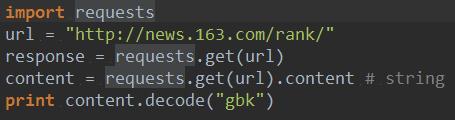
在Python中我们采用了requests库,首先在程序开始要导入该库。所给的url属于get请求方式,简单来说,无需我们向服务器发送一些其他用户相关的数据就可以得到服务器响应的结果。
通过get方式我们得到了response对象。在Pycharm中可以看到response的数据结构,其中我们想要的内容就在content这个字符串中。
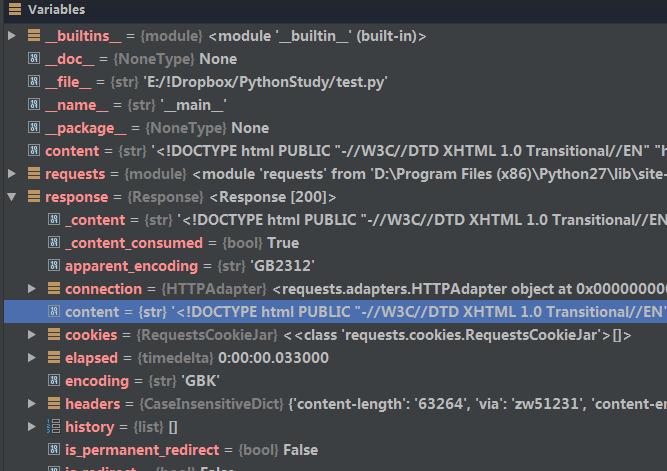
打印该字符串,如果我们直接采用print content,在终端打印出来的可能包含乱码。这是什么原因呢?
因为中文网站中包含中文,而终端不支持gbk编码,所以我们在打印时需要把中文从gbk格式转为终端支持的编码,一般为utf-8编码。一般在对字符串进行处理时,都需要我们对其编码进行转换,转成unicode编码。在终端输出时自动由unicode转换成其支持的编码,比如说utf-8编码。
当然,我们也可以采用print content.decode(“gbk”).encode(“utf-8″),在程序中就把打印的字符串转成utf-8编码了。打印结果就是我们从浏览器看到的网页源代码。
至此,我们实现了获取网页源代码。后面的任务就是如何从这写乱七八糟的源代码中“大海捞针”,筛选出我们需要的数据,本文就先不说了。
类似的,利用Python自带的urllib2实现同样功能如下: