Hive介绍
Hive是一个构建于Hadoop顶层的数据仓库。它依赖于HDFS和MapReduce,对HDFS数据提供类似于SQL的操作,可以将SQL语句转换为MapReduce任务进行运行。这样,Hive实现了以SQL查询方式来分析存储在HDFS中的数据,使得不熟悉MapRe...
fireling
7年前 (2017-11-29) 6353℃
4喜欢
在Linux上操作时,可能会有误删的情况,或者是我们在折腾了一顿(增删查改)之后有点小后悔,想对一个小时或者一天前的文件进行“回滚”恢复,那该怎么去做呢?rsync便是不二之选。
大家都知道,对文件的移动、复制常用的操作命令有mv、cp及scp。其中,mv是移动文件命令,将一个...
fireling
8年前 (2017-11-21) 7376℃
5喜欢
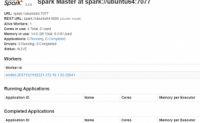
以前看过Hadoop及Spark的相关资料,最近又搭建了Hadoop及Spark集群,“反刍”了一下,发现目前的新版本与以前又有了一些变化。Hadoop目前发布了3版本,而Spark已经更新到了2.2版本。本文主要讲一下Spark的搭建及使用。
使用Spark会用到Hadoop...
fireling
8年前 (2017-11-21) 6422℃
1喜欢