在我们采用用户名密码登陆网站的过程中,或者提交一些信息的过程中,经常会遇到提示用户名输入验证码的情况,而且每次刷新,验证码都会随机生成不一样的数字或字母序列,甚至文字序列。而这段验证码字符序列,就是生成在图片之中,与网页文本格式不同,验证码图片里面的字符序列不仅风格迥异,有时不好用肉眼轻易看清楚,而且其中的真值信息,也不太容易通过一些复制粘贴的操作手段得到。
比如说,我们伟大的国家队网站12306,如图所示,就需要用户输入验证码之后才能登陆。
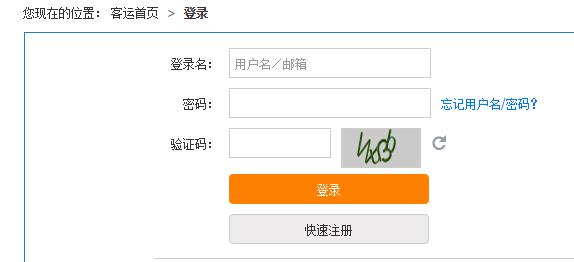
为什么要用验证码?要是网站不采用验证码,可能会导致什么样的后果?
其实这涉及到网站安全的一些问题。一般采用验证码是为了防止机器对网站的暴力操作,比如说自动注册、登录、灌水等,因为得到验证码图片里面的字符序列信息,目前人还是比机器精准很多,所以这有效地避免了外来的一些恶意对网站造成的影响。
但是实际上,往往又有一些需要机器自动去实现操作网站的情况,尤其是在网络抓取数据的时候,需要机器像人一样很轻松地把验证码的空格准确的填上,从而顺利实现后面的操作。那么问题来了,如何进行验证码识别呢?
验证码识别属于OCR的一种典型的情况,它涉及到了模式识别过程中的字符训练、图像处理、字符的分类和识别等流程。
在以后的教程中,我将给大家介绍当年自己在新浪网实习时采用的Google Tesseract-OCR识别引擎。基于Tesseract来对验证码进行训练库的生成以及对特定风格验证码的识别。