GitHub传送门
有很多开源的网络爬虫,如果我们掌握某一种或多种开源的爬虫工具,再我们获取数据的道路上会如虎添翼,事半功倍。这里我介绍一下我对于Scrapy网络爬虫的学习和搭建。
Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
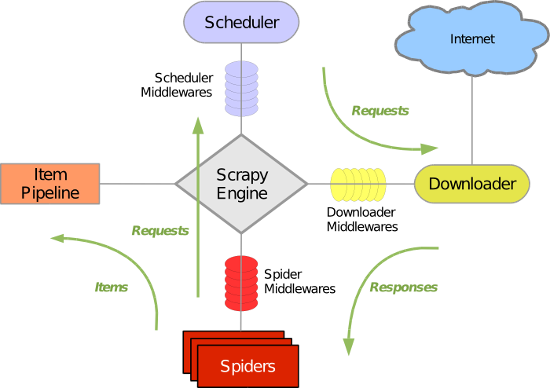
Scrapy要包括了以下组件:
- 引擎,用来处理整个系统的数据流处理,触发事务。
- 调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
- 项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
- 下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
首先安装Scrapy。在Windows和Linux下各有不同的办法,推荐在Linux下使用。一句话搞定:
pip install scrapy1、首先搭建工程:比如说我要建立一个工程,名字叫Wechatproject
输入命令:scrapy startproject Wechatproject(project名称)
那么生成的工程目录如下:
Wechatproject ├── Wechatproject │ ├── __init__.py │ ├── items.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ └── __init__.py └── scrapy.cfg
scrapy.cfg 是整个项目的设置,主要用于部署scrapy的服务,一般不会涉及。
items.py 定义抓取结果中单个项所需要包含的所有内容。【目标】
settings.py 是scrapy的设置文件,可对其行为进行调整。【设置】
在配置文件中开启pipline插件,添加
ITEM_PIPELINES = ['Wechatproject.pipelines.WechatprojectPipeline'] # add settings
如果需要下载images,添加
ITEM_PIPELINES = {'Wechatproject.pipelines.WechatprojectPipeline':1, 'Wechatproject.pipelines.MyImagesPipeline':2} # add settings
IMAGES_STORE = './images'
pipelines.py 定义如何对抓取到的内容进行再处理,例如输出文件、写入数据库等。【处理】
只有一个需要实现的方法:process_item。如果输出文件、写入数据库等,需要设置settings.py文件。
如果需要下载images,添加:
'''if you want to download images'''
# from scrapy.http.request import Request
# from scrapy.contrib.pipeline.images import ImagesPipeline
# class MyImagesPipeline(ImagesPipeline):
# #@TODO
# def get_media_requests(self, item, info):
# for image_url in item['image_urls']: # item['image_urls'] contains the image urls
# # yield Request(image_url)
# yield Request(image_url, meta={'name': item['name']}) # item['name'] contains the images name
# def item_completed(self, results, item, info):
# return super(MyImagesPipeline, self).item_completed(results, item, info)
# def file_path(self, request, response=None, info=None):
# f_path = super(MyImagesPipeline, self).file_path(request, response, info)
# f_path = f_path.replace('full', request.meta['name'])
# return f_path
# ##########################################################
# # import hashlib
# # image_guid = hashlib.sha1(request.url).hexdigest() # change to request.url after deprecation
# # return '%s/%s.jpg' % (request.meta['name'], image_guid)
# pass
# # from scrapy.contrib.pipeline.media import MediaPipeline
# # class MyMediaPipeline(MediaPipeline):
# # #@TODO
# # pass
spiders 目录下存放写好的spider,也即是实际抓取逻辑。【工具】
parse()方法可以返回两种值:BaseItem,或者Request。通过Request可以实现递归抓取(from scrapy.http import Request)。
如果要抓取的数据在当前页,可以直接解析返回item。
例如:yield item
如果要抓取的数据在当前页指向的页面,则返回Request并指定parse2作为callback。
如果要抓取的数据当前页有一部分,指向的页面有一部分.这种情况需要用Request的meta参数把当前页面解析到的数据传到parse2,后者继续解析item剩下的数据。
2、将来上述文件加入工程,便于文件管理
在Wechatproject工程目录下,新建Spider_Main.py,内容如下:
from scrapy.cmdline import execute import sys sys.argv = ["scrapy", "crawl", "wechat"] execute()
3、在spider文件夹下定义spider。
spider定义三个主要的、强制的属性:
name【spider的标识】; start_urls【一个需要爬取的链接起始列表】; parse()【调用时传入每一个url传回的Response对象作为参数,Response是传入这个方法的唯一参数】。
Scrapy为爬虫的start_urls属性中的每个url创建了一个scrapy.http.Request对象,这些scrapy.http.Request首先被调度,然后被执行,之后通过爬虫的parse()方法作为回调函数,scapy.http.Response对象被返回,结果也被反馈给爬虫。
parse()方法是用来处理Response对象,返回爬取的数据,并且获得更多等待爬取的链接。
可以使用其他分析方法如正则表达式或者BeautifulSoup对response.body进行分析,不局限于xpath()方法。
from scrapy.selector import Selector sel = Selector(response) # sel是一个selector
sel.xpath()返回selectors列表,每一个selector表示一个xpath参数表达式选择的节点这样就可以更快的获取需要的数据。
使用sel.xpath().extract()取出节点下面的文本数据或者使用sel.xpath().re(r”(\w+)”)来正则匹配其中元素。
同理,
from scrapy.selector import HtmlXPathSelector hxs = HtmlXPathSelector(response)
使用hxs.select()返回htmlxpathselectors列表,和hxs.select().extract()取出数据或者hxs.select().re(r”(\w+)”)来正则匹配。
4、网络抓取:scrapy crawl wechat(spider名称) 或 scrapy crawl wechat -o results\items.json -t json
转载请注明:宁哥的小站 » 基于Scrapy网络爬虫的搭建



